先週は週末も含め、画面まわりの改善に時間を費やしましたが、HDMIのV-SYNC IRQをトリガとしたDMA転送の実装は、同期や動作確認が取れずにことごとく失敗。代わりにDMAをポーリングで監視する方法も試しましたが、ポーリングしてもDMAの状態が一切変化せず、値も返らないという状態で機能せず。コードを大幅に改造しすぎて元の状態に戻すのも困難になり、挫折感の大きい週末となりました。
気晴らしに、Z80エミュ部分のスピード改善に集中することにした。
Z80エミュを 10MHz まで上げたい!
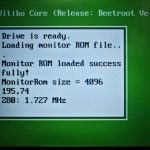
最初、とりあえず動作するようになった Z80エミュですが、当初は実機を下回る。1.727MHz
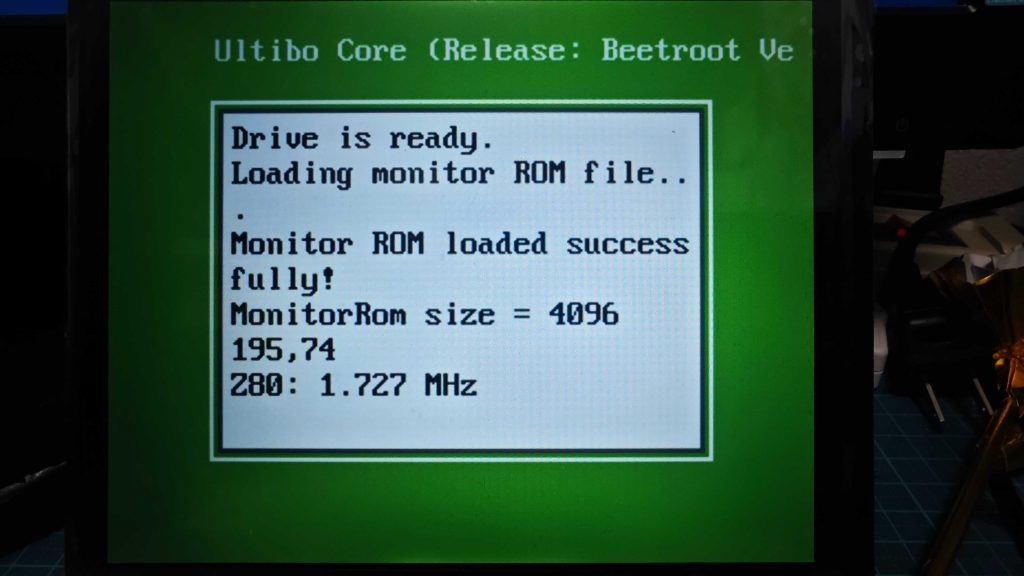
エミュなのでいうなれば、内部的な構造はZ80インタプリタという感じではあるが、Cortex-A53(64-bit)@ 1GHz のマシンで 1.7MHz では、なんとも悲しいではないか。ここに画面描画 Thread が動いたら、どんだけ遅いんだってことになってしまいます。
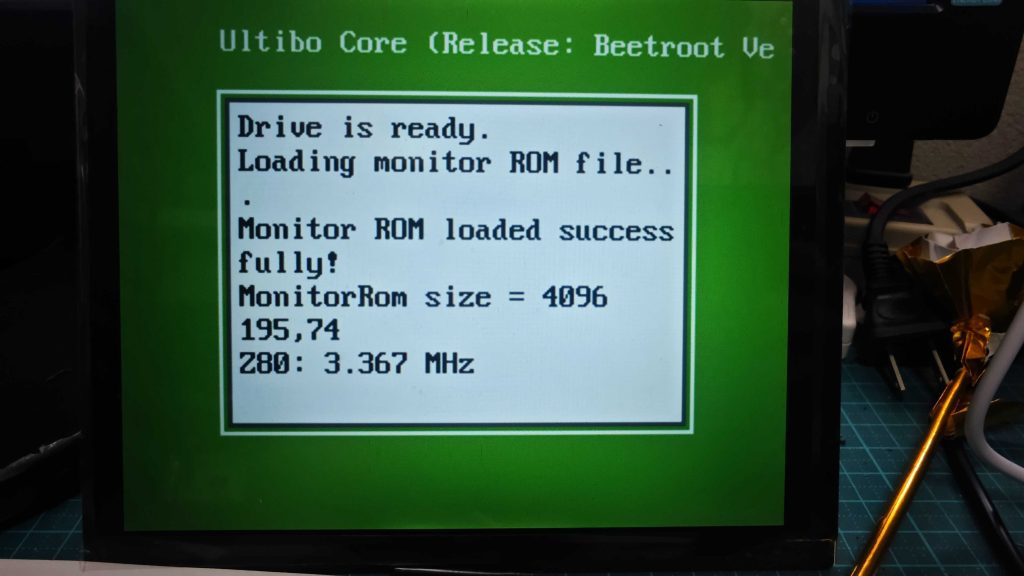
それで、いろいろとムダ改善 ( 工場らしい単語だね ) を行いまして、スピードは徐々に改善し、3.367MHz と約2倍に。
それでも、まだまだということで、絞りまくって、なんと 6.098MHz まで到達。
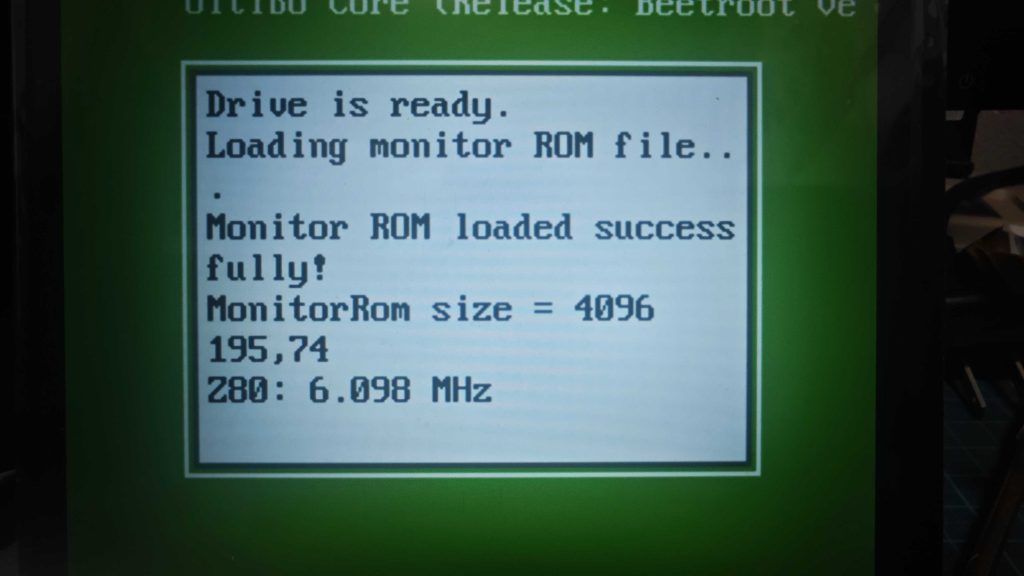
とりあえずここまでくれば、一段落。
今回、どんなことをしてスピードを上げたのか。箇条書きで記します。
Z80エミュレーション スピードアップ施策(時系列)
【初期】〜 1.73MHz 程度
- Z80の命令実行部を関数ポインタ配列で管理(Opc_mainなど)
初期は Delphi 的なスタイルで、オペコードごとにメソッド参照で分岐。
- Z80_RDMEM/Z80_WRMEMの抽象化
メモリアクセスを関数化したが、処理分岐が多く遅延の原因に。可能な限りダイレクトにメモリの読み書きをするように書き換え。
- Z80のClass化を廃止、Cライクにべた書き
意外にこれはすごく大きく改善した。Class は便利だが、やはり動作は遅くなることがわかった。
【中期】〜 約3〜5MHz台
4. 関数ポインタ呼び出しの高速化検討
Opc_main[opcode]() での呼び出しが遅いか検証。
5. 命令デコードの分岐を単純
caseやif-elseの多重分岐を避け、直接ジャンプに近い構造に。
6. 読み出し回数が多いところでのムダな関数呼び出し排除
関数呼び出しがネストしていっている部分がかなりムダが多かった。
【最適化フェーズ】〜 約6.06MHz 到達
7. 変数の型のオバースペックを解消
なんとなく Int32 となっていたところを、厳格に Word (UInt16) にしたり、byte (Uint8) にしたら、内部的なムダなキャスト処理が減ったということで、これも大きくスピードアップに貢献
8. メモリマップドI/Oを早期に除外
MZ80がメモリマップドI/Oの構造をとっているため、 $E000~$E008 のアドレスに読み書きがあったら、pio8255、pit8253 の処理と連動させなくてはいけないので、メモリに読み書きがあるたびに判定を繰り替えしていたが、初期の段階で $E000以前のアドレスだったらすぐに手続き離脱 (exit ) することで、かなり速くなった。
ということで、これからはVRAM描画の最適化に挑戦。 (今のバージョンをバックアップしておこう。。)